Analytical Functions in Oracle SQL
 3shTech (trainings@trishtechnology.com)
3shTech (trainings@trishtechnology.com)
Analytical Functions
RANK , DENSE_RANK
SELECT employee_id,first_name,salary
,department_id
,RANK() OVER (PARTITION BY department_id ORDER BY salary DESC)
"Rank_emp"
,DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC)
"Dense_Rank_emp"
FROM hr.employees
ORDER BY department_id;

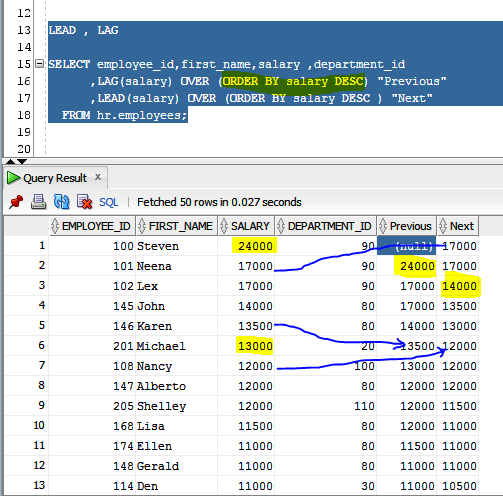
LEAD , LAG
SELECT employee_id,first_name,salary
,department_id
,LAG(salary) OVER (ORDER BY salary DESC) "Previous"
,LEAD(salary) OVER (ORDER BY salary DESC ) "Next"
FROM hr.employees;
REGEXPR_SUBSTR
The
regular expression matching information. It can be a combination of the
following:
|
Value |
Description |
|
^ |
Matches the beginning of a string.
If used with a match_parameter of 'm', it matches the start
of a line anywhere within expression. |
|
$ |
Matches
the end of a string. If used with a match_parameterof 'm', it
matches the end of a line anywhere within expression. |
|
* |
Matches zero or more occurrences. |
|
+ |
Matches
one or more occurrences. |
|
? |
Matches zero or one occurrence. |
|
. |
Matches
any character except NULL. |
|
| |
Used like an "OR" to
specify more than one alternative. |
|
[
] |
Used
to specify a matching list where you are trying to match any one of the
characters in the list. |
|
[^ ] |
Used to specify a nonmatching list
where you are trying to match any character except for the ones in the list. |
|
(
) |
Used
to group expressions as a subexpression. |
|
{m} |
Matches m times. |
|
{m,} |
Matches
at least m times. |
|
{m,n} |
Matches at least m times, but no
more than n times. |
|
\n |
n
is a number between 1 and 9. Matches the nth subexpression found within ( )
before encountering \n. |
|
[..] |
Matches one collation element that
can be more than one character. |
|
[::] |
Matches
character classes. |
|
[==] |
Matches equivalence classes. |
|
\d |
Matches
a digit character. |
|
\D |
Matches a nondigit character. |
|
\w |
Matches
a word character. |
|
\W |
Matches a nonword character. |
|
\s |
Matches
a whitespace character. |
|
\S |
matches a non-whitespace
character. |
|
\A |
Matches
the beginning of a string or matches at the end of a string before a newline
character. |
|
\Z |
Matches at the end of a string. |
|
*? |
Matches
the preceding pattern zero or more occurrences. |
|
+? |
Matches the preceding pattern one
or more occurrences. |
|
?? |
Matches
the preceding pattern zero or one occurrence. |
|
{n}? |
Matches the preceding pattern n
times. |
|
{n,}? |
Matches
the preceding pattern at least n times. |
|
{n,m}? |
Matches the preceding pattern at
least n times, but not more than m times. |
start_position
Optional.
It is the position in string where the search will start. If
omitted, it defaults to 1 which is the first position in the string.
nth_appearance
Optional.
It is the nth appearance of pattern in string. If
omitted, it defaults to 1 which is the first appearance of pattern in string.
match_parameter
Optional.
It allows you to modify the matching behavior for the REGEXP_SUBSTR function.
It can be a combination of the following:
|
Value |
Description |
|
'c' |
Perform case-sensitive matching. |
|
'i' |
Perform
case-insensitive matching. |
|
'n' |
Allows the period character (.) to
match the newline character. By default, the period is a wildcard. |
|
'm' |
expression is
assumed to have multiple lines, where ^ is the start of a line and $ is the
end of a line, regardless of the position of those characters in expression.
By default, expression is assumed to be a single line. |
|
'x' |
Whitespace characters are ignored.
By default, whitespace characters are matched like any other character. |
Examples:
Example - Match on Words
Let's start by extracting
the first word from a string.
For example:
SELECT REGEXP_SUBSTR ('TechOnTheNet is a great resource', '(\S*)(\s)')FROM dual; Result: 'TechOnTheNet '
This example will return
'TechOnTheNet ' because it will extract all non-whitespace characters as
specified by (\S*) and then the first
whitespace character as specified by (\s). The result will include both the first word as well as the space
after the word.
If you didn't want to
include the space in the result, we could modify our example as follows:
SELECT REGEXP_SUBSTR ('TechOnTheNet is a great resource', '(\S*)')FROM dual; Result: 'TechOnTheNet'
This example would return
'TechOnTheNet' with no space at the end.
REGEXPR_SUBSTR realtime examples:
1)
SELECT REGEXP_SUBSTR ('3shTech is a great resource', '(\S*)(\s)')
FROM
dual;
o/p:
'3shTech
'
2)
SELECT REGEXP_SUBSTR ('3shTech is a great resource', '(\S*)')
FROM
dual;
o/p:
'3shTech'
3)
SELECT REGEXP_SUBSTR ('3shTech is a great resource', '(\S*)' ,1,1)
FROM dual;
memory:
--3shTech
o/p:
'3shTech'
4)
SELECT REGEXP_SUBSTR ('3shTech is a great resource', '(\S*)(\s)' ,1,2)
FROM dual;
memory:
--3shTech
--is
--a
--great
o/p:
'is '
Oracle / PLSQL: REGEXP_INSTR Function
This Oracle tutorial explains how to use the
Oracle/PLSQL REGEXP_INSTR function with
syntax and examples.
Description
The Oracle/PLSQL REGEXP_INSTR function is an
extension of the INSTR function. It returns the location of a regular expression pattern in
a string. This function, introduced in Oracle 10g,
will allow you to find a substring in a string using regular expression pattern
matching.
Syntax
The syntax for the REGEXP_INSTR function in
Oracle is:
REGEXP_INSTR( string, pattern [, start_position [, nth_appearance [, return_option [, match_parameter [, sub_expression ] ] ] ] ] )Parameters or Arguments
string
The string to search. string can be CHAR, VARCHAR2,
NCHAR, NVARCHAR2, CLOB, or NCLOB.
pattern
The regular expression matching information.
It can be a combination of the following:
|
Value |
Description |
|
^ |
Matches the
beginning of a string. If used with a match_parameter of
'm', it matches the start of a line anywhere within expression. |
|
$ |
Matches the end of a string. If
used with a match_parameterof
'm', it matches the end of a line anywhere within expression. |
|
* |
Matches zero
or more occurrences. |
|
+ |
Matches one or more occurrences. |
|
? |
Matches zero
or one occurrence. |
|
. |
Matches any character except
NULL. |
|
| |
Used like an
"OR" to specify more than one alternative. |
|
[ ] |
Used to specify a matching list
where you are trying to match any one of the characters in the list. |
|
[^ ] |
Used to
specify a nonmatching list where you are trying to match any character except
for the ones in the list. |
|
( ) |
Used to group expressions as a
subexpression. |
|
{m} |
Matches m
times. |
|
{m,} |
Matches at least m times. |
|
{m,n} |
Matches at
least m times, but no more than n times. |
|
\n |
n is a number between 1 and 9.
Matches the nth subexpression found within ( ) before encountering \n. |
|
[..] |
Matches one
collation element that can be more than one character. |
|
[::] |
Matches character classes. |
|
[==] |
Matches
equivalence classes. |
|
\d |
Matches a digit character. |
|
\D |
Matches a nondigit
character. |
|
\w |
Matches a word character. |
|
\W |
Matches a
nonword character. |
|
\s |
Matches a whitespace character. |
|
\S |
matches a
non-whitespace character. |
|
\A |
Matches the beginning of a
string or matches at the end of a string before a newline character. |
|
\Z |
Matches at
the end of a string. |
|
*? |
Matches the preceding pattern
zero or more occurrences. |
|
+? |
Matches the
preceding pattern one or more occurrences. |
|
?? |
Matches the preceding pattern
zero or one occurrence. |
|
{n}? |
Matches the preceding
pattern n times. |
|
{n,}? |
Matches the preceding pattern at
least n times. |
|
{n,m}? |
Matches the
preceding pattern at least n times, but not more than m times. |
start_position
Optional. It is the position
in string where
the search will start. If omitted, it defaults to 1 which is the first position
in the string.
nth_appearance
Optional. It is the nth
appearance of pattern in string. If omitted, it defaults to
1 which is the first appearance of pattern in string.
return_option
Optional. If a return_option of 0 is
provided, the position of the first character of the occurrence of pattern is returned. If
a return_option of
1 is provided, the position of the character after the occurrence of pattern is returned. If
omitted, it defaults to 0.
match_parameter
Optional. It allows you to modify the matching
behavior for the REGEXP_INSTR function. It can be a combination of the
following:
|
Value |
Description |
|
'c' |
Perform
case-sensitive matching. |
|
'i' |
Perform case-insensitive
matching. |
|
'n' |
Allows the period
character (.) to match the newline character. By default, the period is a
wildcard. |
|
'm' |
expression is assumed to
have multiple lines, where ^ is the start of a line and $ is the end of a
line, regardless of the position of those characters in expression. By default, expression is assumed to be
a single line. |
|
'x' |
Whitespace
characters are ignored. By default, whitespace characters are matched like
any other character. |
subexpression
Optional. This is used when
pattern has subexpressions and you wish to indicate which subexpression in pattern is the target. It is
an integervalue from 0 to 9 indicating the subexpression to match on in pattern.
Returns
The REGEXP_INSTR function returns a numeric
value.
If the REGEXP_INSTR function does not find any occurrence of pattern,
it will return 0.
Note
- If there are conflicting
values provided for match_parameter,
the REGEXP_INSTR function will use the last value.
- If you omit the match_behavior parameter,
the REGEXP_INSTR function will use the NLS_SORT parameter to determine if
it should use a case-sensitive search, it will assume that string is a
single line, and assume the period character to match any character (not
the newline character).
REAL TIME examples:
EXAMPLES:
1)
SELECT REGEXP_INSTR ('The example shows how to use the REGEXP_INSTR function',
'ow', 1, 1, 0, 'i')
FROM
dual;
O/P:
15
-- i.e starting position of 'ow'
2)
SELECT REGEXP_INSTR ('The example shows how to use the REGEXP_INSTR function',
'ow', 1, 1, 1, 'i')
FROM
dual;
O/P:
17--
i.e ending position of 'ow'



Comments
Post a Comment